

🧠 Olympus.io: How Our RAG Engine Transforms Enterprise File Storage into AI Superpowers
Introduction
Enterprise data lives across complex ecosystems — file servers, NAS systems, and document libraries. Unlocking insights from that unstructured data in a secure, compliant, and scalable way has historically been difficult.
At Olympus.io, we’ve built a platform that connects directly to these enterprise file stores and uses Retrieval-Augmented Generation (RAG) to deliver rich, AI-powered answers via natural language. Here’s a behind-the-scenes look at how our RAG system works.
🔁 Olympus.io’s RAG Pipeline: From Storage to AI Insight
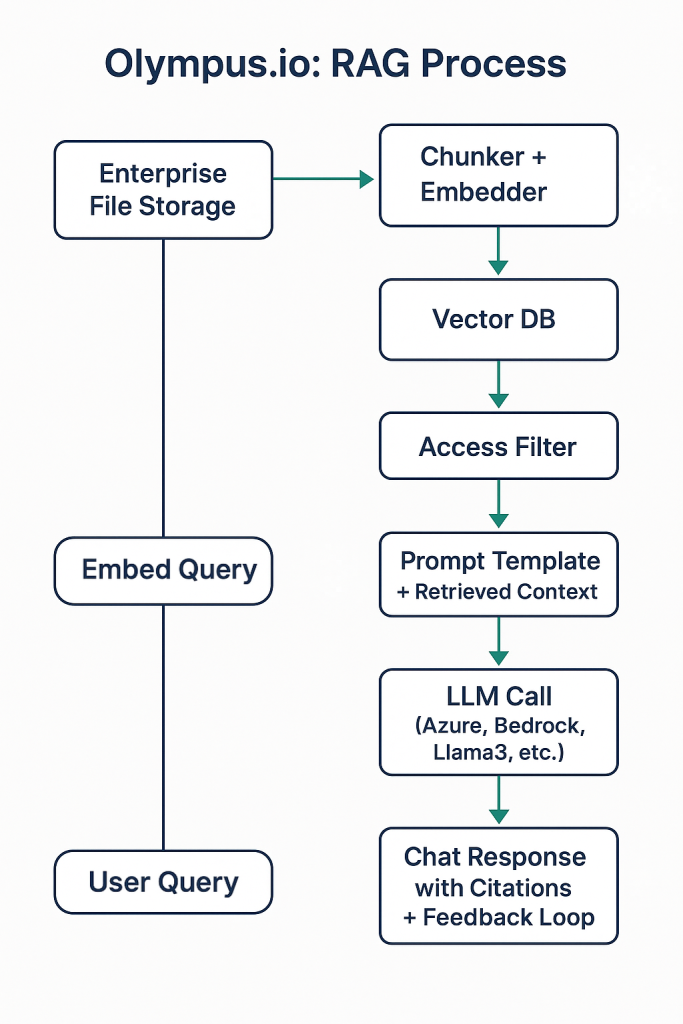
1. Connect & Index
-
Connectors securely mount on-premises or cloud-hosted NAS/file servers.
-
File metadata (names, timestamps, permissions) and content (PDFs, Office docs, txt, etc.) are extracted.
-
Documents are chunked into semantically relevant sections using advanced heuristics and token-aware chunking.
2. Embed & Store
-
Each chunk is transformed into a vector embedding using a configurable model (e.g., OpenAI, Cohere, HuggingFace, or customer-hosted LLMs).
-
Embeddings are stored in a secure vector database (such as Weaviate or FAISS, depending on deployment).
3. Query & Retrieve
-
When a user enters a query via our AI chat interface:
-
The query is embedded using the same model family.
-
A similarity search pulls the top-k document chunks.
-
Olympus.io applies access controls to ensure only authorized documents are retrieved.
-
4. Augment & Generate
-
Retrieved context is passed into a prompt template along with the user query.
-
The prompt is sent to the customer’s preferred LLM (Azure AI, Bedrock, Gemini, or a private model like Llama 3).
-
The model generates a grounded, traceable answer.
5. Respond & Learn
-
Results are returned in the Olympus.io chat interface (web, iOS, Android).
-
Citations link to the original file source.
-
Feedback and interaction data can be used to improve embeddings and chunking strategies.
- The illustration below shows a high-level architecture of the end-to-end RAG process
💡 Why Olympus.io’s RAG Is Different
-
Enterprise-Grade Security: Your data never leaves your control. We deploy on-prem or in your VPC.
-
LLM Agnostic: Use your preferred model provider or bring your own open-source model.
-
Mobile + Browser Access: Access your AI from anywhere, fully secure.
-
Built-in Governance: Native file permissions, audit trails, and user-level data boundaries.
- Role-Based Access Control: Enforce Active Directory File-based access permissions so users only can chat with documents for which they have permission
Conclusion
Olympus.io’s RAG-powered platform gives enterprises a private, intelligent interface to query their own documents — making enterprise search as intuitive as chatting with an AI.